This article delves into the examination of user reviews and ratings on Flipkart. These reviews serve as a valuable resource for informing others about their experiences and, importantly, provide insights into product quality and brand reputation. Through this analysis, we aim to offer users valuable information about products and suggest ways to improve product quality.
Here we will be applying Machine Learning to analyze the data and make prediction, either if a product review is positive or negative.
Before going into the analysis and code, you can download the data from this link.
Since we are using python here we will be using libraries & module like Pandas, Seaborne, Matplotlib, Scikit, NLTK etc. From the coding perspective i am using Jupyter Notebook which best for analysis and machine learning tasks.
So first we will import our required modules and libraries in jupyter.

Now if you have downloaded the dataset from the given link , import it using pandas and use the head keyword.

Since we have only two columns review and ratings and since ratings columns is the labeled columns lets check for unique ratings using unique keyword of pandas.

So we can see that each customers have given ratings out of 5, so based on our requirement we have to prepare a model which can predict if a a review is positive or negative so here we will separate positive and negative reviews add a another column names label.

After adding labels to the data model we have to preprocess data, here in this step we have to remove stopwords from reviews, cleaning, stemming, etc to get clean model for our prediction. So here is the function which will do the preprocess step.

Now lets preprocess the reviews column using the predefined function. Here we have used Tqdm library to see the progress of preprocessing. To know more about this tqdm library you can visit its documentation.
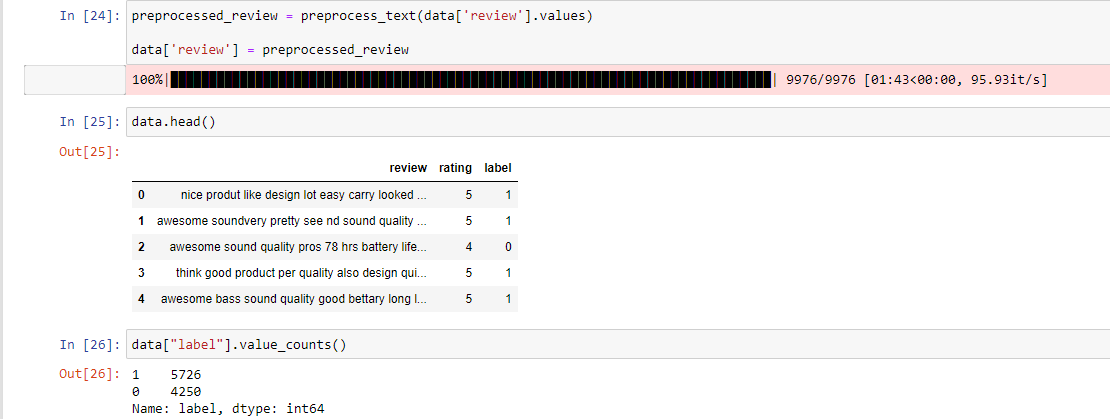
Wo we can clearly see the positive(1) ratings are more than the negative(0) ratings.
No we have to convert text to vector using TF-IDF (Term Frequency Inverse Document Frequency) and split into train and test set.
About TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) is a technique used in natural language processing and text analysis to represent the importance of words in a document relative to a collection of documents (corpus). It's typically used for document-level analysis, not individual sentences. However, you can certainly apply TF-IDF to a sentence within the context of a larger document or corpus.
Here's a general process to apply TF-IDF to a sentence within a larger text:
1. Preprocessing: Tokenize the text into words or terms. You may need to perform additional preprocessing steps like lowercasing, removing punctuation, and stemming or lemmatization.
2. TF-IDF Calculation:
- Term Frequency (TF): Calculate the term frequency of each term in the sentence. Term frequency is the number of times a term (word) appears in the sentence.
- Document Frequency (DF): Calculate the document frequency of each term within the larger document or corpus. Document frequency is the number of documents in the corpus that contain the term.
- Inverse Document Frequency (IDF): Compute the IDF, which is the logarithm of the total number of documents divided by the document frequency. It measures how unique a term is across the corpus.
- TF-IDF Score: Multiply the TF by the IDF for each term in the sentence. The result is the TF-IDF score for each term in the sentence.
So here we created a vector with max feature of 500. So that we can predict the from short reviews also.

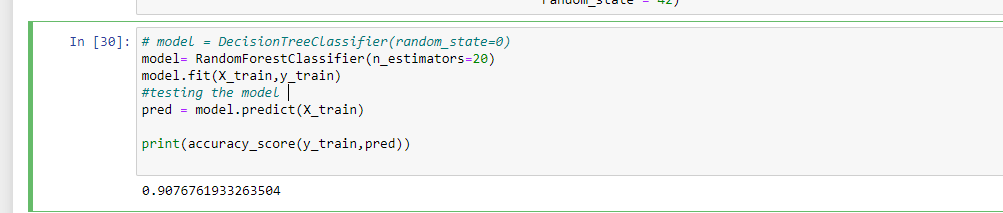
Now we have to train our model, here i am using Random Forest classifier to prepare our model with 30 level depth if you want you can use decision tree also. With Random Forest i got an accuracy of around 90-95 percent.

Comments
Post a Comment